Microservices Adoption in 2020
Everyone’s talking about microservices. Who’s actually doing it?
 Chaos Clock. (source: San Jaya Prime on Wikimedia Commons)
Chaos Clock. (source: San Jaya Prime on Wikimedia Commons)
Microservices seem to be everywhere. Scratch that: talk about microservices seems to be everywhere.
And that’s the problem. Thinkers as dissimilar as Plato, Robert Boyle, and Keith Richards tend to agree about one thing: Talk is cheap. So we wanted to determine to what extent, and how, O’Reilly subscribers are empirically using microservices. In other words, how long have people been using them? What are they using them for? Are they having success? If so, what kinds of benefits are they seeing? What can we learn from their failures?

Learn faster. Dig deeper. See farther.
So we did what we usually do: we ran a survey. The survey ran from January 31, 2020 through February 29; we had 1502 respondents from the readers of our mailing lists. Here’s a summary of our key findings:
Most adopters are successful with microservices.
A minority (under 10%) reports “complete success,” but a clear majority (54%) describes their use as at least “mostly successful” and 92% of the respondents had at least some success.
Microservices practices are surprisingly mature
About 28% of respondents say their organizations have been using microservices for at least three years; more than three-fifths (61%) of the respondents have been using microservices for a year or more.
Adopters are betting big on microservices
Almost one-third (29%) of respondents say their employers are migrating or implementing a majority of their systems (over 50%) using microservices.
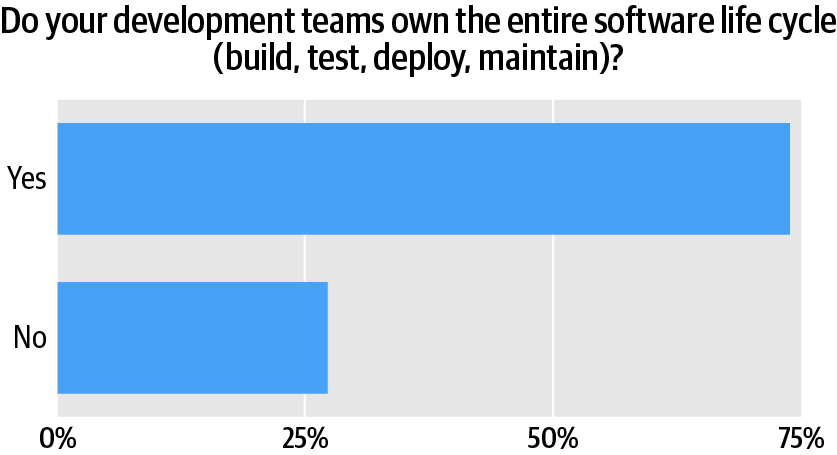
Success with microservices means owning the software lifecycle
Most (74%) respondents say their teams own the build-test-deploy-maintain phases of the software lifecycle. Teams that own the lifecycle succeed at a rate 18% higher than those that don’t.
Success with containers
Respondents who used containers to deploy microservices were significantly more likely to report success than those who didn’t. For our audience, use of containers is one of the strongest predictors of success with microservices.
It’s the culture
A plurality of adopters cite cultural or mindset barriers to adoption. Decomposing monolithic applications into microservices is also a major challenge, but complexity may be the biggest challenge of all.
Respondent Demographics
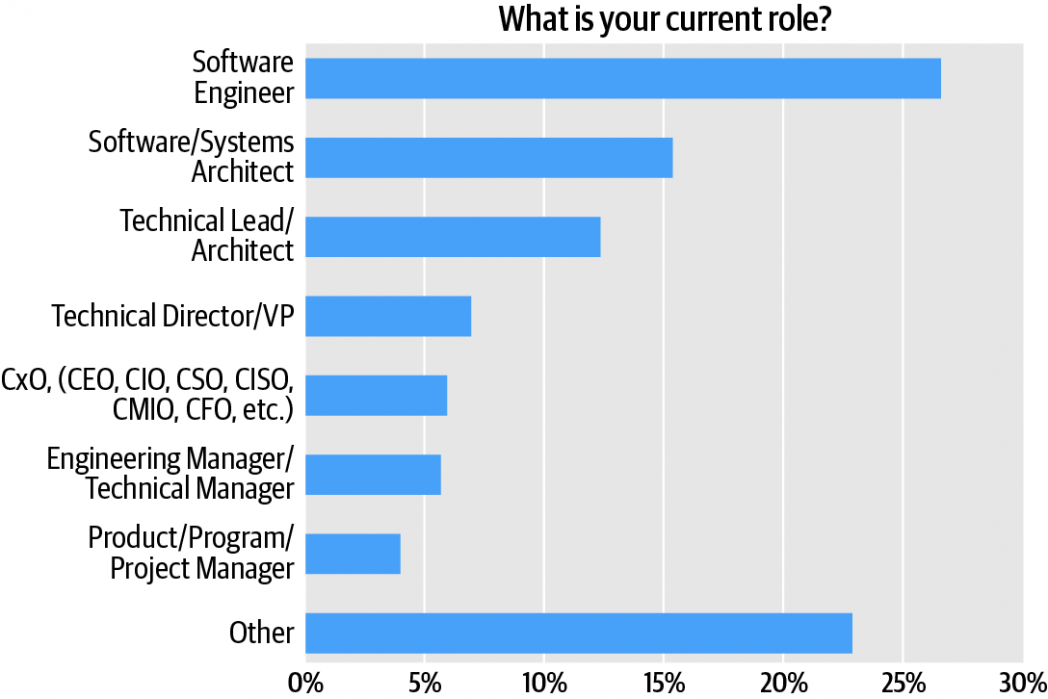
Technical roles dominate, but management roles are represented, too. Software engineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). If you combine the different architectural roles—i.e., software and systems architects, technical leads—architects represent almost 28% of the sample. Adding architects and engineers, we see that roughly 55% of the respondents are directly involved in software development. Respondents in management roles constitute close to 23% of the audience; executive-level positions (vice presidents and CxOs) account for roughly 13%, overall.
That said, the audience for this survey—like those of almost all Radar surveys—is disproportionately technical. Technical roles represented in the “Other” category include IT managers, data engineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. Each of these roles comprised less than 3% of all respondents.
Respondents work in more than 25 different vertical industries.The single largest cluster consists of respondents (26%) from the software industry. Combined, technology verticals—software, computers/hardware, and telecommunications—account for about 35% of the audience (Figure 2).
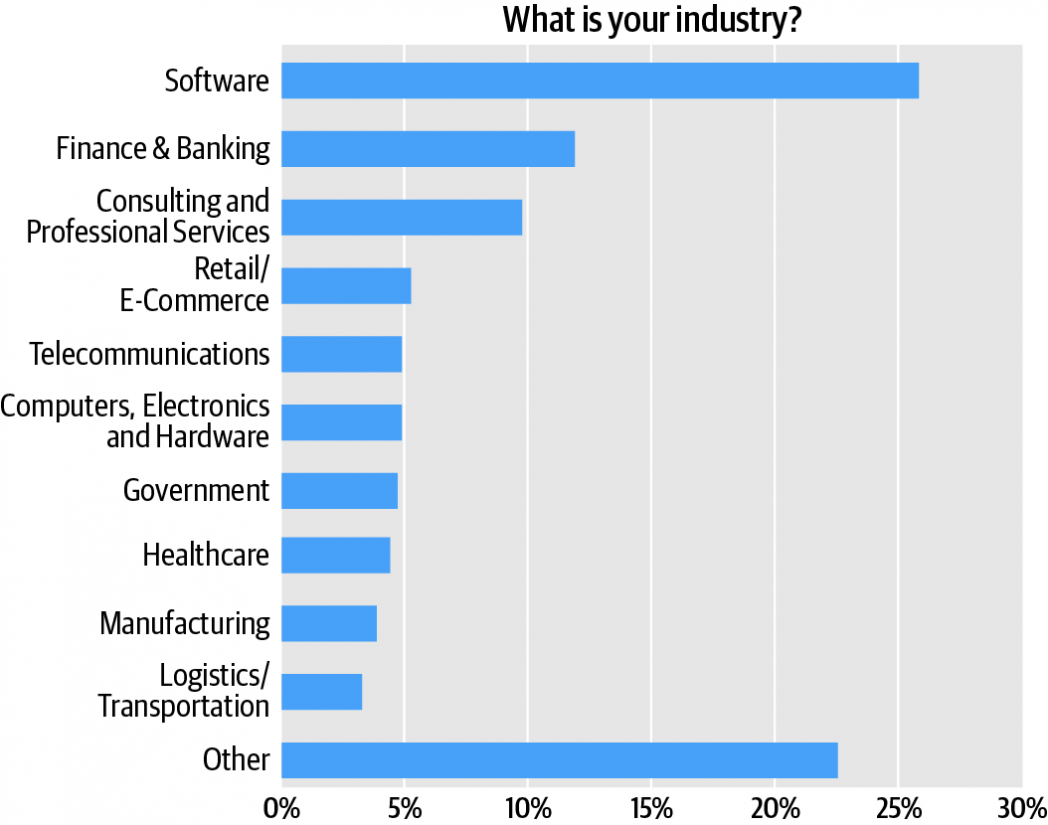
The second-largest cluster (exclusive of “Other”) was finance, at close to 12%, followed by consulting/professional services, at roughly 10%. The “Other” category, at more than 22% of the total, includes respondents from education (3%, combining K12 and higher education), insurance (3%), energy and utilities (2%), media/entertainment (2%), non-profit (2%), consumer products (1%) and other verticals.
Microservices aren’t just for the big guys. Large companies are amply represented, and respondents affiliated with organizations of 1,000 or more employees comprise 42% of the audience. Overall, however, small- and medium-sized organizations predominate. The largest single cluster (33% of all respondents) was organizations with under 100 employees.
A good global mix. We’re used to seeing a North American-centric tilt in our Radar surveys. This is true, too, of the audience for this survey, nearly half of which (over 49%) works in North America. Europe—inclusive of the United Kingdom—was the next largest region, comprising almost 26% of all respondents. Asia-Pacific accounts for roughly 15% of respondents. In total, just over half of the audience hails from outside of North America. This roughly mirrors usage on the O’Reilly learning platform.
Microservices Adoption: Explication and Analysis
Slightly more than one-third of respondents say their organizations have been using microservices for between 1 and 3 years (Figure 3). This is the single largest cluster in our sample. The second-largest cluster, at nearly one-quarter (over 23%) of respondent organizations, does not use microservices at all. Mature adopters, companies that first adopted microservices between 3 and 5 years ago, comprise the third-largest cluster, at 18%. If you factor in the respondents whose organizations first adopted microservices over 5 years ago, this means that more than 28% of respondent organizations have been using microservices for at least three years. A little under one-sixth of companies (15%) are just beginning microservice adoption, however; they’ve been using microservices for less than 1 year.
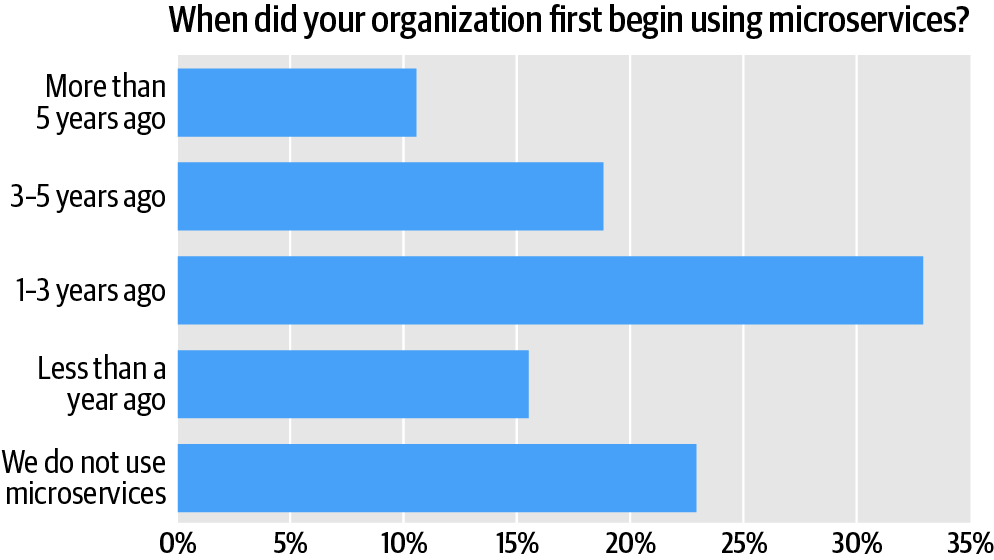
The pace of adoption, in which a clear majority (61%) of respondents say their organizations have used microservices for between 1 and 5 years, roughly tracks with empirical trends we’ve observed internally (e.g., with respect to keyword search and topic usage activity on the O’Reilly online learning platform) and in other contexts. The share of adoption for the 12-month period between January of 2019 and January of 2020 likewise suggests that microservices remains a topic of interest to O’Reilly users. On the other hand, there’s evidence from other quarters that interest in microservices—both as a topic and as a general search term—has flattened (and perhaps even cooled) over the 12 months.
So not only are most respondents using microservices, but three-fifths (61%) have been using them for a year or more. But do they describe their experience as successful? What share of the systems they’re deploying or maintaining are built to microservices architecture? What characteristics do successful adopters share? What can we learn from those who say they’ve failed with microservices?
Critical Factors for Success
A majority of respondents (55%) say their organization’s use of microservices has been either a “complete success” (close to 9%) or “mostly successful” (Figure 4).
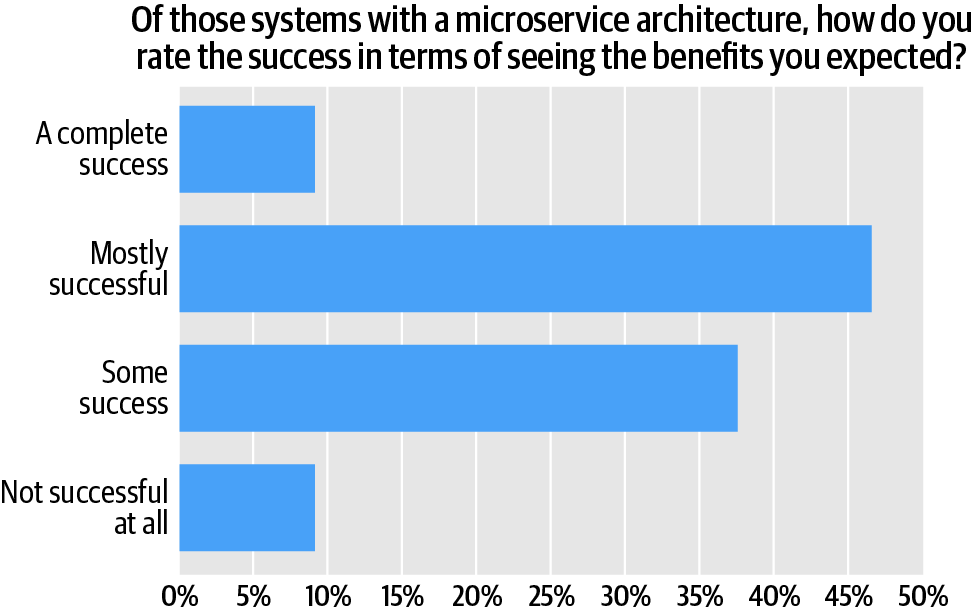
More than one-third (37%) say they’ve had “some success” with microservices. Approximately 8% say they haven’t been successful at all. However, relationships in the data hint at several critical factors for success. For example, in organizations in which development teams own the entire development cycle (i.e., building, testing, deployment, and maintenance), close to half (almost 49%) also reported being “mostly successful” with microservices—and more than 10% said their microservices development efforts were a “complete success. (Figure 5). The combined tally (close to 59%) is about 18% higher than the baseline tally for the survey audience as a whole.
Do we see meaningful connections between success with microservices and the use, or disuse, of specific technologies? Perhaps; we’ll take a look at that next, specifically with respect to containers, centrally managed databases, and monolithic UIs. The semantics get a bit twisted, but the connections we identify seem more strongly associated with “disuse” than with “use.”
We emphasize the qualifier “seem” because—with respect to the problem of identifying factors for success—we lack detailed data to draw rigorous conclusions. We kept our survey simple; our priority was to develop a general sense of how, why, and in which scenarios people are using microservices. For the most part, our questions didn’t drill down into specifics. We emphasize “seem” for another reason, too. When we asked respondents to cite the biggest challenges to microservices adoption, two problems—decomposition and complexity—stood out for us. Decomposition because it came in at #2, trailing only corporate culture / mindset, which (in almost all Radar surveys) is #1; complexity because two ostensibly different kinds of complexity—“increased complexity” (#4) and the “complexity of managing many services” (#5)—cracked the top 5. Add them together and respondents view complexity in one form or another as the biggest challenge.
The upshot is that complexity in general and (more specifically) the complexity associated with decomposition are the shoals in which most microservices projects seem to run aground. That’s hard to argue with; complexity is rarely (if ever) associated with success. But it’s easy to pretend that complexity is the enemy when it’s really only one variable in a set of tradeoffs.
What does that mean? Although it’s not a question we asked, anecdotally we hear that most microservices projects are replacing large, legacy, monolithic software systems. Those monoliths are themselves very complex, having evolved over decades. The complexity of the monolith that’s being replaced is a “sunk cost” that has only partially been paid; it continues to extract a toll as that software is extended to support new features, changing business models, changing modes of user interaction, and more. Microservices may require paying a complexity cost again, but that’s where the tradeoff comes in: in return for the complexity of re-engineering the system, you get increased flexibility, including a simpler path to adding new features, simpler management, simplified scaling as the organization grows.
Use of Containers for Microservice Deployment
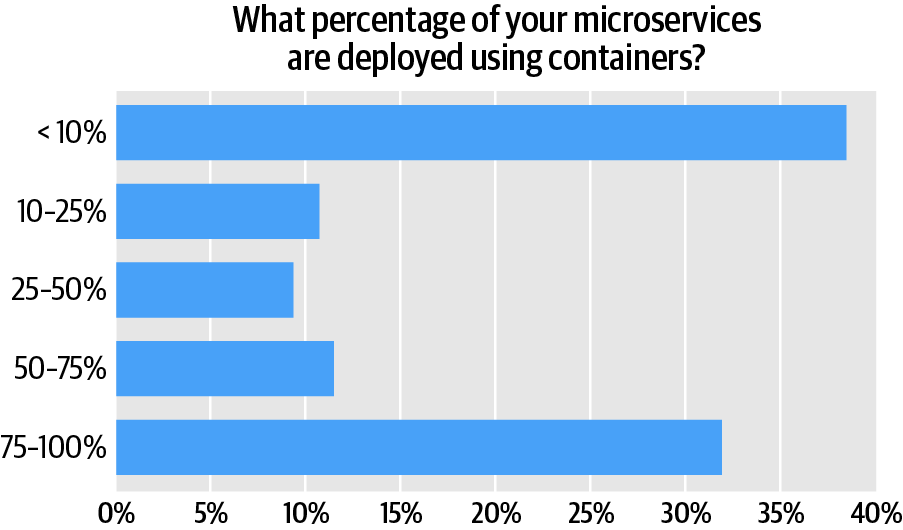
We asked respondents what proportion of their microservices they deploy using containers.
The largest single cluster (38%) for this question consists of respondents that do not deploy their microservices in containers. One might reasonably expect that containers would be the most common means of instantiating microservices. This just isn’t the case, however. Our findings indicate that, for our survey audience as a whole, most respondents (58%) deploy microservices using some medium other than containers (Figure 6).
There are valid reasons not to use containers. For some adopters, technical debt (in the form of custom-built, proprietary and monolithic systems, applications, or architectures) is a constraining factor. So it just makes sense to instantiate microservices at the level of the virtual machine (VM), as distinct to that of the container. Or maybe it’s faster and less costly, at least in the short term, to build and instantiate microservices as non-virtualized code running in the context of a conventional operating system, a database, application server, etc..
This doesn’t mean respondents aren’t using containers; most of the survey audience is. It’s just that containers are not yet the most popular means of instantiating microservices, although that could be changing. For example, the second-largest cluster (31%) for this question consists of organizations that deploy between 75% and 100% of their microservices using containers. And 11% use containers to deploy between 50 and 75% of their microservices.
The upshot is that more than two-fifths (42%) of respondent organizations use containers to deploy at least half of their microservices—and that, for the survey audience as a whole, nearly two-thirds (62%) are using containers to deploy at least some of their microservices. So we have a split: on the one hand, most microservices are instantiated using a technique other than containers; on the other hand, most organizations that use microservices also instantiate at least some of them in containersFor example, 10% of respondents say they use containers to deploy between 10-25% of their microservices; a little more than 9% deploy between 25-50% of microservices with containers; and, again, 11% deploy between 50-75% using containers.1 It seems adopters either go (mostly) all-in on containers, using them for most microservices, or use them sparingly.
There’s a critical, and intriguing, “but” here: a higher than average proportion of respondents who report success with microservices opt to instantiate them using containers; conversely, a much higher proportion of respondents who describe their microservices efforts as “Not successful at all” do not instantiate them in containers. For example, almost half (49%) of respondents who describe their deployments as “a complete success” also instantiate most of their microservices (75-100%) in containers. This is more than 5x the baseline (9%) for this question. Conversely, an overwhelming majority (83%) of respondents who describe their microservices efforts as “Not successful at all” are instantiating them by some means other than containers. (These are respondents who use containers in conjunction with less than 10% of their microservices.) This is about 11x the baseline for this question (Figure 4).
This observation makes intuitive sense. With microservices, instead of deploying one monolithic application, you may need to deploy and manage hundreds or thousands of services. Using containers to standardize deployment, and container orchestration tools to automate ongoing management, greatly simplifies the burden of deployment and management. It’s worth remembering that “containers” get their name by analogy to shipping containers: instead of loading a ship with 10,000 cases of canned soup, 20,000 board-feet of lumber, and a few thousand automobile tires, the shippers would pack their goods in standardized containers that could be stacked up on the ship. This represents a significant reduction in the cost of shipping–or the operational cost of deploying and maintaining software. Containers are a simplifying technology.
Use of a Central, Managed Database
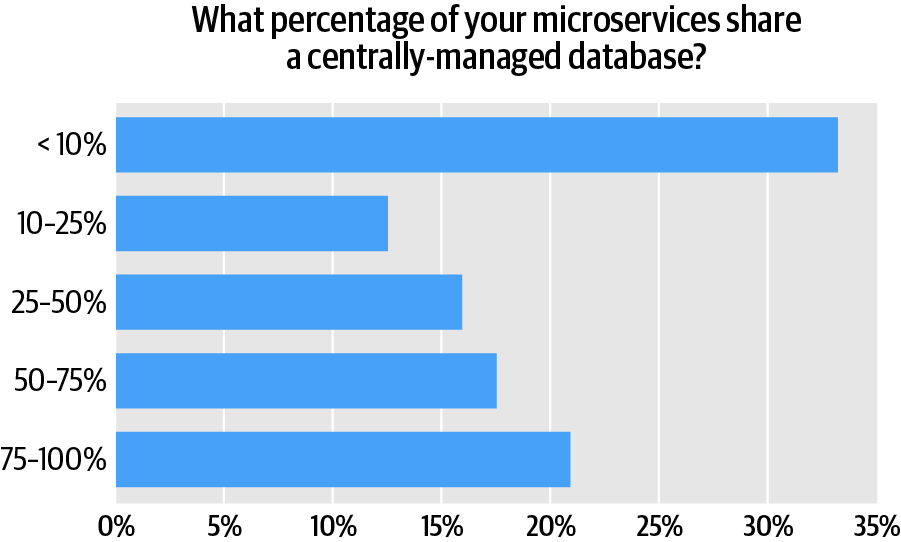
When we asked respondents what proportion of their microservices share a central, managed database (Figure 7), we found that not using a centrally managed database with microservices tends to be associated with failure. That said, the question itself (i.e., “What percentage of your microservices share a centrally-managed database?”) doesn’t give us much to go on. We don’t know what respondents considered a centrally managed database; what kind of database they were using (relational or non-relational); or whether transactional integrity was an issue.
Granted that there’s a lot we’d like to know that we don’t, let’s think about why this question is important, and dig a bit deeper. The point of microservices is breaking an application into separate, decoupled services. Using the database as the integration point between services is counter to this purpose. The result is a software system that looks like it’s built from microservices, but really isn’t, and which realizes few of the promised advantages because the individual services are still coupled to each other at the database layer.
Are our respondents succeeding with decoupled databases? For our survey audience, it looks like the smaller the proportion of microservices that share access to a central, managed database, the greater the likelihood of failure. Think of this as what survivorship bias is most apt to miss: i.e., failure. The lesson in such cases is usually that failure tells a valuable story of its own.
Of the respondents who said that they are “not successful at all,” 71% said that they did not make much use of a centrally managed database (under 10% of their microservices). The problem is that we don’t actually know what using (or not using) a centrally managed database entails because the question itself is imprecise. For example, a recommended practice is to implement a separate namespace for each microservice. This can be accomplished in several ways—including by using a centralized database!2 But implementing a separate namespace for each service raises a number of hard problems, starting with transactional integrity and data consistency, and (notionally) encompassing security and privacy, too. Working through these issues isn’t easy, even with a centralized database. It’s much harder without one, however.
However, while it’s easy to look at these failures and suppose that using a separate database (or database schema) per service is a bad idea that leads to failure, that’s far from the whole picture. Think back to where we started this section: microservices represents a tradeoff of complexity against flexibility. (And also a tradeoff of complexity now versus complexity accreted over the years in a legacy system–we could perhaps think of paying off technical debt with a big “balloon payment.”) Replacing a legacy monolith with microservices isn’t easy. But working through the current complexity to build a system that’s more likely to serve your future needs is what good engineering is all about. And when you’re building a complex system, you need to know where the pain points are. That’s what this data is really telling us: redesigning databases to eliminate dependencies between services is a significant pain point.
Monolithic UI
We also asked users what percentage of the systems deployed as microservices had a monolithic user interface (Figure 8). This question is also problematic. First, what is a monolithic UI? More to the point, what would our respondents assume we mean by a monolithic UI, and what are they doing if they’re not building a monolithic UI? There are several possibilities, none of which is entirely convincing. One recent trend in web development is “micro frontends”, but this doesn’t appear to be well-known enough to have a significant effect on our data. Respondents are likely to associate a “monolithic UI” with traditional web development (or perhaps even desktop applications or ancient “green screens”), as opposed to the use of components within a framework like React. (Since micro frontends are built with frameworks like React, these may be two names for almost the same thing. Once you’re using a component-based framework, associating components with individual back-end services isn’t a big leap.) In any case, it is likely that a monolithic UI represents a tradeoff for simplicity over flexibility and complexity. A front end built with a modern reactive web framework is almost certainly more flexible–and more complex–than a 1990s-era web form.
Use of a monolithic UI is another possible example of survivorship bias; it’s also another case in which respondents who are successful with microservices are much less interesting than those who aren’t.
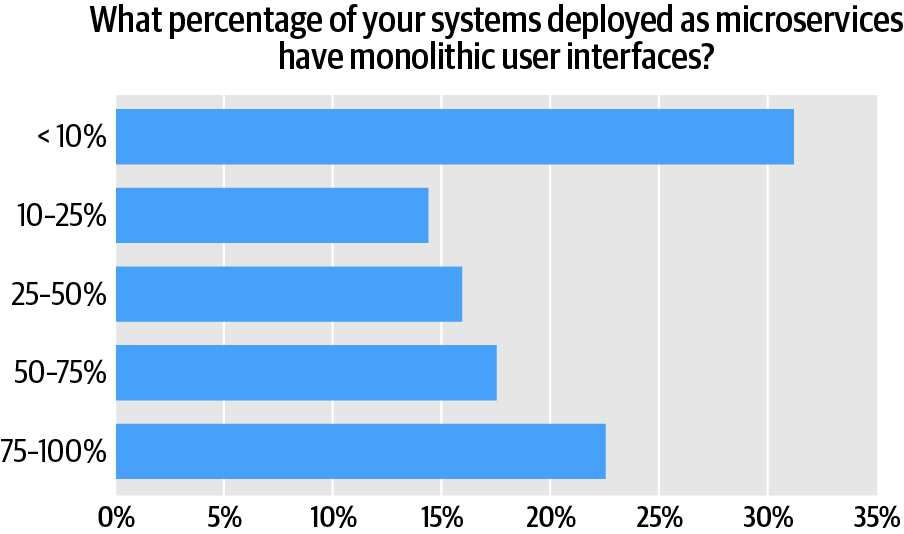
Take the cluster of respondents who don’t build a monolithic UI. (That is, <10% of their microservices use a monolithic UI.) At 31% of all respondents, this is the largest group. But it also has the highest rate of complete failure: 17% describe their implementations as “Not successful at all.” Respondents in this group were also more likely to describe their projects as a “complete success” (12%); 37% said they were “mostly successful.”
At the other end of this spectrum, among respondents who used a monolithic UI for 50-75% of their systems, only 2% said they were not successful at all. 8% said their projects were a “complete success,” while 52% said their projects were “mostly successful.”
What are we to make of this? It’s hard to say, given that the notion of a monolithic UI (and its opposite) are poorly defined. But this looks similar to what we observed for databases. Reactive web frameworks (like React and Angular), which are used to build many modern web interfaces, are very complex systems in their own right. It’s not surprising that systems that don’t use a monolithic UI have a high failure rate, and that systems that implement a monolithic UI have a fairly high success rate; if simplicity for developers were the only criteria, we’d all go back to green screens.
Rather than just looking at a “complexity tax,” we have to consider what the goal is: building systems that can easily be extended and scaled as conditions change. Is a UI that isn’t monolithic (regardless of the technology) more complex? Probably so. Ideally, moving a monolithic application’s back end to microservices while maintaining the legacy front-end would be minimal work (though “minimal” is always more minimal in theory than in practice). What’s gained in return? Additional flexibility; in this case, we’d be looking for the ability to support different kinds of user interfaces and different kind of interactions. Adding a mobile or voice UI to a legacy front end can easily become a nightmare; but it’s hard to imagine any modern application that doesn’t have a mobile front-end, and in a few years, it will be hard to imagine an application without a voice-driven front end. Re-envisioning the front end in terms of services (however they may be implemented) is building flexibility into the system. What other user interfaces will we need in the next few years? Again, the issue is never simply “complexity”; it’s what you get in return.
Benefits and Challenges
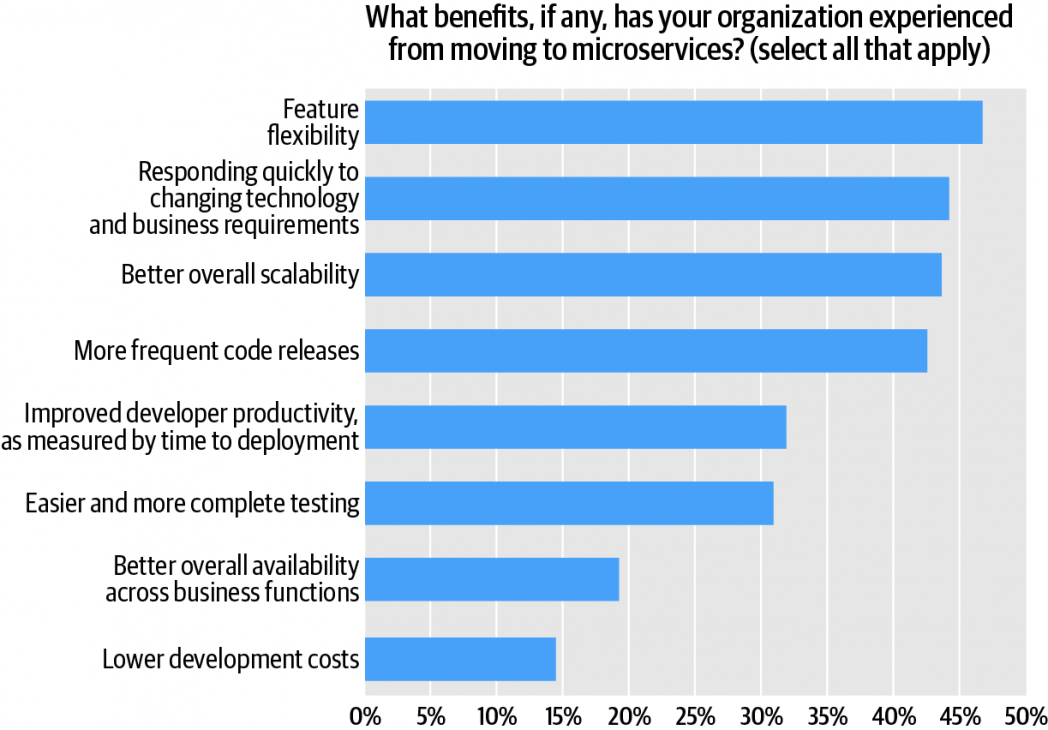
Respondents were asked which benefits, if any, they attribute to their successful use of microservices (Figure 9). They were asked to select all applicable benefits.
The largest cluster for this response (at 45%) named “feature flexibility,” followed (at just under 45%) by “responding quickly to changing technology and business requirements.” Just under 44% cited the benefit of “better overall scalability,” followed (43%) by “more frequent code refreshes.” The least-cited benefit (15%) was that of lower development costs; just 20% of respondents say they realized one of the core promises of microservices: improved availability by virtue of multiple, redundant functions (i.e., services).
Almost all of our Radar surveys have found that respondents cite corporate culture as one of the top two or three impediments to adoption or success. This survey was no exception. Culture was the most oft-cited challenge: almost 40% of respondents cited culture—or, alternatively, the problem of “overcoming existing mindset”—as among the biggest challenges they faced in adopting microservices (Figure 10). This was the largest cluster for this response, followed (37%) by the challenge of decomposing requirements into primitive/granular functions. The challenge of integrating with legacy systems was third, cited by approximately 30% of respondents.
If we combine the two responses that have to do with complexity (“Increased complexity” and “Complexity of managing many services”), we find that complexity in one form or another is the biggest overall challenge, cited by 56% of respondents.
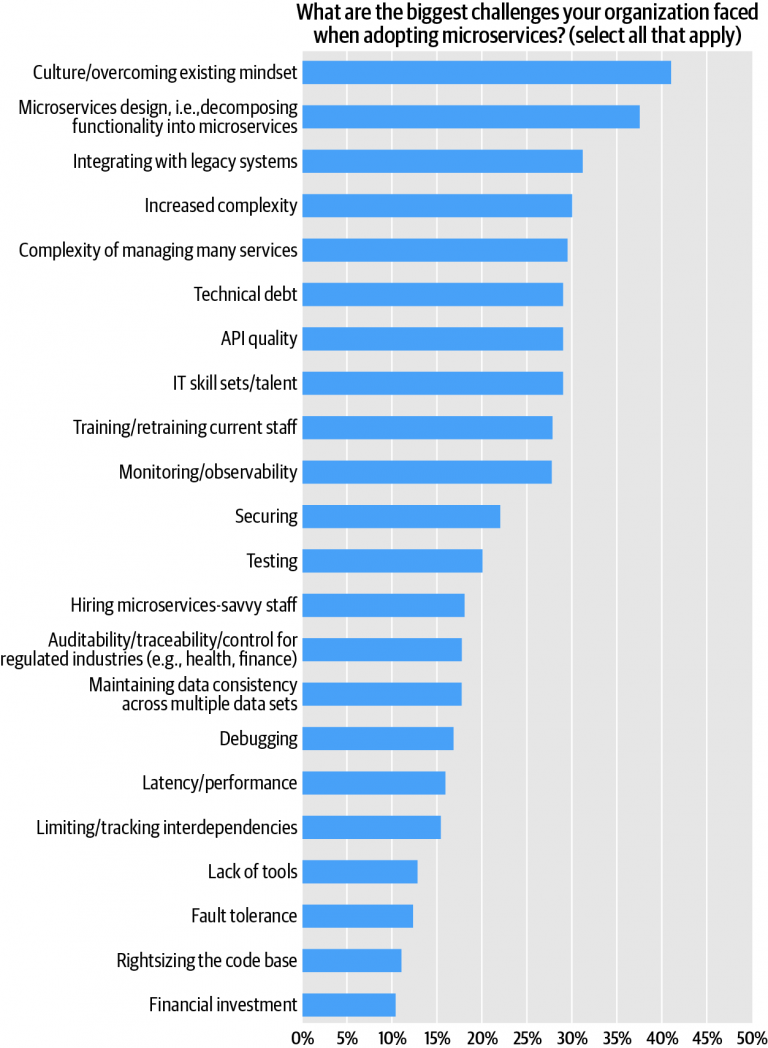
Other results of note: at No. 6, technical debt (cited by 28% of respondents) just missed the top five. It’s the kind of hard problem that cannot be wished, willed, or architected away–indeed, replacing a monolithic system with microservices can be seen as a “lump sum” payment of years of accrued technical debt. The rest of the top 10 reads like a laundry list of hard problems: API quality (28%), talent and skill shortages (28%), training and retraining challenges (also 28%) and monitoring/observability (27%) round out the top 10. The high showing for API quality—i.e., their richness, robustness, transparency, accessibility, stability (over time) and usefulness—shouldn’t be surprising. The relatively low result for security (No. 11, cited by 21% of respondents) is surprising.
Takeaways
For the most part, adopters say they’re having success with microservices: more than half (55%) describe their efforts as at least “mostly” successful. Respondents commonly attribute several clear benefits to their use of microservices, including feature flexibility; the ability to respond to changing business requirements; improved scalability; and more frequent code releases. And, at least among adopters, microservices comprise a growing share of production systems: almost half (46%) of respondents say their organizations are currently developing for or migrating one-quarter or more of their production systems to microservices. Nearly one-sixth (15%) say they’re developing or migrating between 75-100% of their systems to a microservices-oriented architecture. For our audience, microservices architecture is not only established but (for a majority of adopters) used to support systems or workloads in production.
There’s evidence here for the microservices skeptic, too. About 8% of would-be adopters describe their experiences with microservices as “not successful at all.” Proponents will claim that 8% is a shockingly low rate of failure for any software development project, particularly given the historical failure rates of large IT projects; but skeptics will counter that 8% is still, well, 8%. And even if a majority of respondents say they’ve been “mostly successful” with microservices, a sizable percentage (37%) say they’ve had only “some” success. The upshot is that a little under half (45%) of all users have had bad, middling, or only modestly successful experiences with microservices. A skeptic might also point to selection bias: not only is our audience dominated by people in technical roles, but software developers and architects are overrepresented. A survey like this is bound to attract a disproportionate share of participants with an interest in seeing microservices succeed—or fail. In the same way, the person who volunteers her time to complete our survey is more likely than not to be working with or to have an interest in (for or against) microservices. These are all valid objections.
Our results emphasize the importance of pragmatic microservices development. Microservices can be complex–there’s no point in denying that. And complexity frequently leads to failure–there’s no point in denying that, either. Using containers for deployment is a way of minimizing complexity. We’ve seen that decoupling databases is frequently a pain point, along with redesigning the user interface as a set of components. But again, it’s important to recognize that microservices rarely arise out of nowhere. Many microservice projects are replacing existing systems. And that existing system has its own complexity: complexity that grew over the years, complexity that’s preventing you from achieving your current goals. If you’ve become accustomed to your legacy systems, you probably don’t realize how complex they are–but if you’ve made the decision to migrate from a monolith to microservices, the complexity of maintaining your monolith is almost certainly the reason.
Replacing one kind of complexity with another–is that a gain? Absolutely, if it’s done correctly and enables you to achieve your goals. Complexity is an engineering problem, and engineering problems are always about tradeoffs. When you’re building microservices, keep your eye on the goal–whether that’s supporting new features, scaling for more customers, providing a new experience for users, or something else. Don’t be surprised that microservices bring their own complexity, and don’t let that daunt you. But don’t underestimate the challenge, either.
Special thanks to Kristen Haring, Phil Harvey, Mark Madsen, Roger Magoulas, Larry “Catfish” Murdock, Sam Newman, and Mac Slocum for—among other invaluable contributions—questions, comments, context, and, above all, constructive criticism.
Footnotes
1 For example, 10% of respondents say they use containers to deploy between 10-25% of their microservices; a little more than 9% deploy between 25-50% of microservices with containers; and, again, 11% deploy between 50-75% using containers.
2 A development team could use a centrally managed database to create separate namespaces for each service. This practice is notionally consistent with the idea that each microservice should own its data. It also saves developers the headache of coding logic to manage data consistency, transactional durability, and other issues. Or, alternatively, software developers could opt to manage data persistence (along with data consistency and transactional durability) on a per-microservices basis, a practice that is strictly consistent with the idea of data sovereignty, but which radically ups the complexity factor.