Assessing progress in automation technologies
When it comes to automation of existing tasks and workflows, you need not adopt an “all or nothing” attitude.
 Mirror (source: Pixabay)
Mirror (source: Pixabay)
In this post, I share slides and notes from a keynote Roger Chen and I gave at the Artificial Intelligence conference in London in October 2018. We presented an overview of the state of automation technologies: we tried to highlight the state of the key building block technologies and we described how these tools might evolve in the near future.
To assess the state of adoption of machine learning (ML) and AI, we recently conducted a survey that garnered more than 11,000 respondents. As I pointed out in previous posts, we learned many companies are still in the early stages of deploying machine learning:

Learn faster. Dig deeper. See farther.
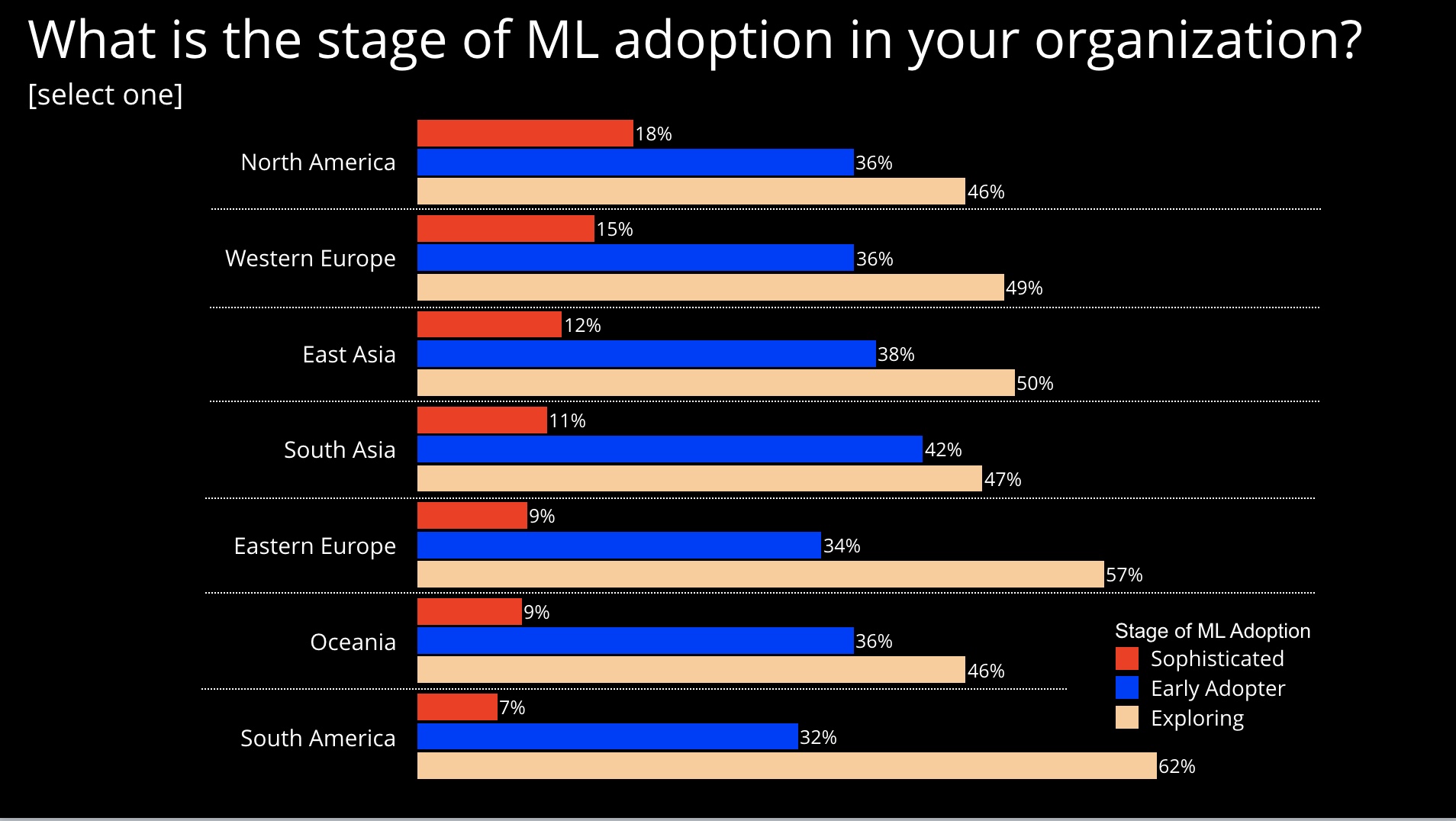
Companies cite “lack of data” and “lack of skilled people” as the main factors holding back adoption. In many instances, “lack of data” is literally the state of affairs: companies have yet to collect and store the data needed to train the ML models they desire. The “skills gap” is real and persistent. Developers have taken heed of this growth in demand. In our own online learning platform, we are seeing strong growth in usage of content across AI topics, including 77% growth in consumption of content pertaining to deep learning:
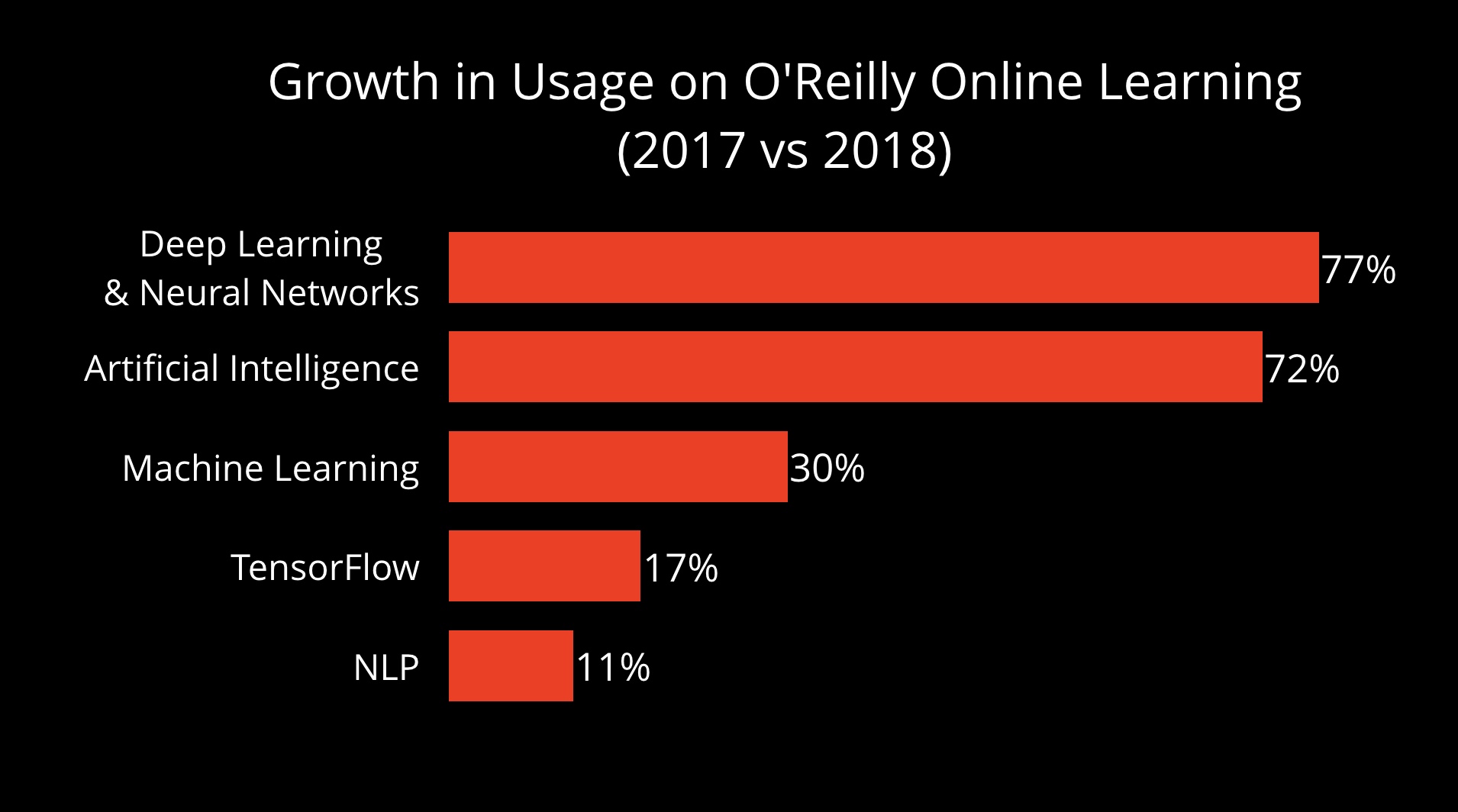
We are also seeing strong growth in interest in new tools and topics such as PyTorch and reinforcement learning. In the case of reinforcement learning, new tools like Ray are already spurring companies to examine alternative solutions to multi-step decision problems, where models might be hard to build using supervised learning.
Decision-makers also are investing in AI and automation technologies. A recent survey of close to 4,000 IT leaders across 84 countries found that more companies are starting to invest in AI and automation technologies:
- The level of investment depends on the company. Companies that already consider themselves digital leaders tend to report a much higher level of investment in AI and automation.
- Location also matters. Given the highly competitive business environment in China, it’s no surprise that companies there also tend to invest at a much higher rate. This aligns with a recent overview on AI in China delivered by Kai-Fu Lee at our AI conference in San Francisco this past September.
Progress in AI technologies has been fueled by the growth in data and improvements in compute and models. Let’s briefly examine each of these elements.
Deep learning models
Resurgence in deep learning began in 2011/2012 with record-setting models for speech recognition and computer vision. When I first began following deep learning in 2013, the community was small and tight-knit. Best practices were passed through internships in a few groups, and a lot of knowledge was shared in the form of “oral tradition.” Today, the community is much larger.
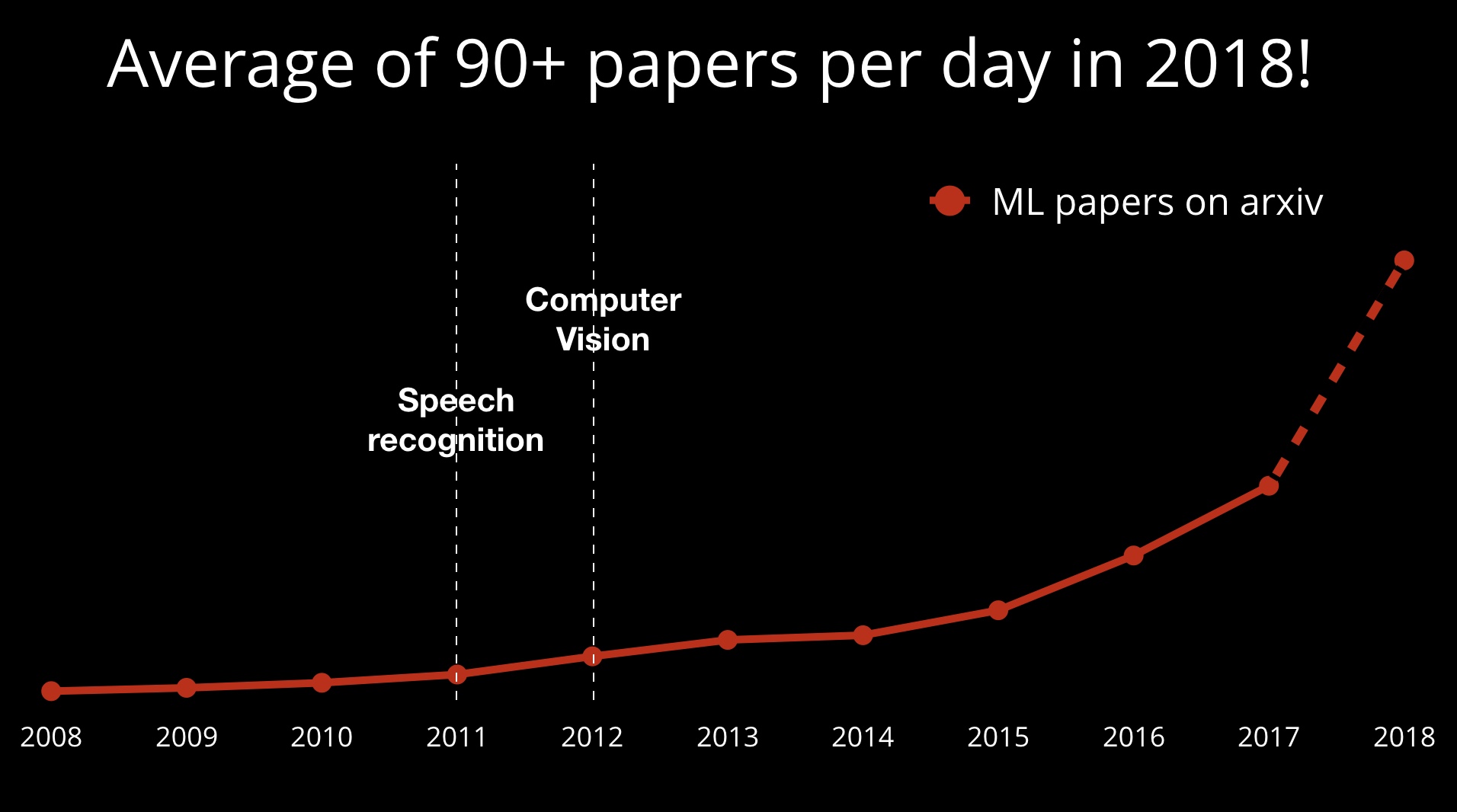
Progress in research has been made possible by the steady improvement in: (1) data sets, (2) hardware and software tools, and (3) a culture of sharing and openness through conferences and websites like arXiv. Novices and non-experts have also benefited from easy-to-use, open source libraries for machine learning.
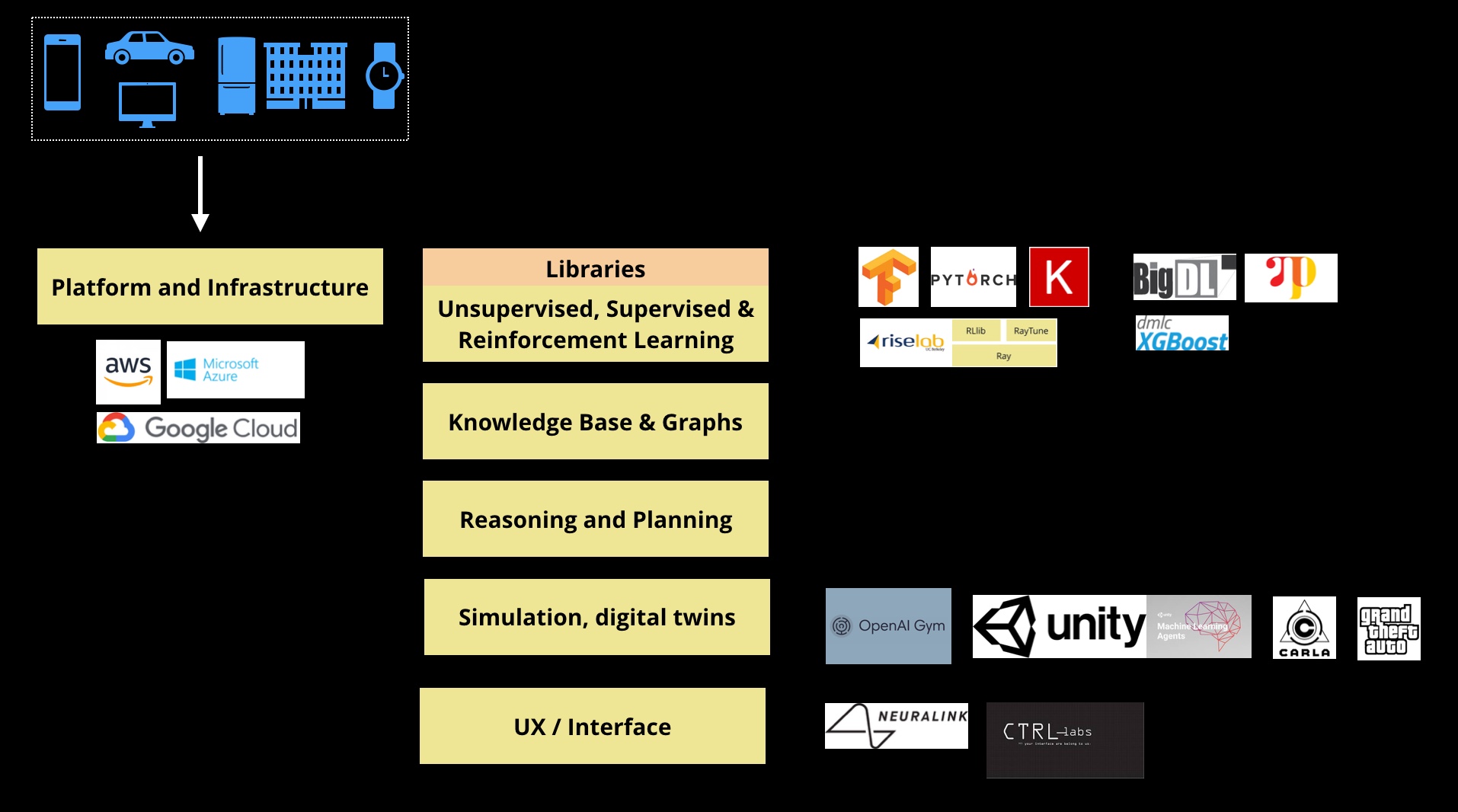
These open source ML libraries have leveled the playing field and have made it possible for non-expert developers to build interesting applications. In fact, in 2017 we featured a couple of talented teenagers (Kavya Kopparapu and Abu Qader) at our AI conferences. They both were self-taught, and both were able to build potentially high-impact prototypes involving deep learning.
Companies have taken notice and want to build ML and AI into their systems and products. In 2015, LinkedIn ran a study and found that the U.S. had a national surplus of people with data science skills. That’s no longer the case today:
- Demand in key metro areas in the U.S. is extremely high.
- Cutting-edge skills like AI and machine learning will likely spread to other industries and geographies in the future.
Data
With that said, having great models isn’t sufficient. At least for now, many of the models we rely on—including deep learning and reinforcement learning—are data hungry. Since they have the potential to scale to many, many users, the largest companies in the largest countries have an advantage over the rest of us. China, in particular, has been dubbed “the Saudi Arabia of data.” Because AI research depends on having access to large data sets, we’re already seeing more cutting-edge research coming out of the large U.S. and Chinese companies. NIPS used to be a sleepy academic conference. Now it sells out within minutes, and we’re seeing more papers coming from large U.S. and Chinese companies.
The good news is that there are new tools that might help the rest of us gain access to more data. Services for generating labeled data sets are increasingly using AI technologies. The ones that rely on human labelers are beginning to use machine learning tools to help their human workers scale, improve their accuracy, and make training data more affordable. In certain domains, new tools like GANs and simulation platforms are able to provide realistic synthetic data that can be used to train machine learning models.
In addition to data generation, another important aspect is data sharing. There are also new startups building open source tools to improve data liquidity. These startups are using tools like cryptography, blockchains, and secure communication to build data networks that enable organizations to share data securely.
Compute
Machine learning researchers are constantly exploring new algorithms. In the case of deep learning, this usually means trying new neural network architectures, refining parameters, or exploring new optimization techniques. As Turing Award winner David Patterson describes it, “The appetite for training is unlimited!”
The challenge is that experiments can take a long time to complete: hours, days, or even weeks. Computation also can cost a lot of money. This means researchers cannot casually run such long and complex experiments, even if they had the patience to wait for them to finish.
We are in year seven of this renewed interest in AI and deep learning. At this stage, companies know the types of computations involved and they are beginning to see enough demand to justify building specialized hardware to accelerate those computations. Hardware companies, including our partner Intel, continue to release suites of hardware products for AI (including compute, memory, host bandwidth, and I/O bandwidth). The demand is so great that other companies—including ones that aren’t known for processors—are beginning to jump into the fray.

More help is on the way. We see a lot of new companies working on specialized hardware. You have hardware for the data center, where the task of training large models using large data sets usually takes place. We are also entering an age where billions of edge devices will be expected to perform inference tasks, like image recognition. Hardware for these edge devices needs to be energy efficient and reasonably priced.
Numerous hardware startups are targeting deep learning both in China and in the U.S. The San Francisco Bay Area, in particular, is a hotbed for experienced hardware engineers and entrepreneurs, many of whom are working on AI-related startups. As you can see below, many hardware startups are targeting edge devices:

Closing thoughts
We’ve talked about data, models, and compute mainly in the context of traditional performance measures: namely, optimizing machine learning or even business metrics. The reality is that there are many other considerations. For example, in certain domains (including health and finance) systems need to be explainable. Other aspects including fairness, privacy and security, and reliability and safety are also all important considerations as ML and AI get deployed more widely. This is a real concern for companies. In a recent survey, we found strong awareness and concern over these issues on the part of data scientists and data engineers.
Consider reliability and safety. While we can start building computer vision applications today, we need to remember that they can be brittle. In certain domains, we will need to understand safety implications and we will need to prioritize reliability over efficiency gains provided by automation. The founders of Mobileye described it best: the main parameter in the race for autonomous cars cannot be who will have the first car on the road.
Developing safe, explainable, fair, and secure AI applications will happen in stages. When it comes to automation of existing tasks and workflows, you need not adopt an “all or nothing” attitude. Many of these technologies can already be used for basic and partial automation of workflows.

Related content:
- Meredith Whittaker on “What shapes the AI that’s shaping our world?”
- “The next generation of AI assistants in enterprise”
- “How to think about AI and machine learning technologies, and their roles in automation”
- “What machine learning means for software development”
- Kai-Fu Lee on “China: AI superpower”
- David Patterson on “A new golden age for computer architecture”