Universal API Access from Postgres and SQLite
 The Whirlpool Galaxy (Spiral Galaxy M51, NGC 5194). (source: NASA and the European Space Agency on Wikipedia Commons)
The Whirlpool Galaxy (Spiral Galaxy M51, NGC 5194). (source: NASA and the European Space Agency on Wikipedia Commons)
In “SQL: The Universal Solvent for REST APIs” we saw how Steampipe’s suite of open source plug-ins that translate REST API calls directly into SQL tables. These plug-ins were, until recently, tightly bound to the open source engine and to the instance of Postgres that it launches and controls. That led members of the Steampipe community to ask: “Can we use the plug-ins in our own Postgres databases?” Now the answer is yes—and more—but let’s focus on Postgres first.
NOTE: Each Steampipe plugin ecosystem is now also a standalone foreign-data-wrapper extension for Postgres, a virtual-table extension for SQLite, and an export tool.

Learn faster. Dig deeper. See farther.
Using a Steampipe Plugin as a Standalone Postgres Foreign Data Wrapper (FDW)
Visit Steampipe downloads to find the installer for your OS, and run it to acquire the Postgres FDW distribution of a plugin—in this case, the GitHub plugin. It’s one of (currently) 140 plug-ins available on the Steampipe hub. Each plugin provides a set of tables that map API calls to database tables—in the case of the GitHub plugin, 55 such tables. Each table can appear in a FROM or JOIN clause; here’s a query to select columns from the GitHub issue, filtering on a repository and author.
select
state,
updated_at,
title,
url
from
github_issue
where
repository_full_name = 'turbot/steampipe'
and author_login = 'judell'
order by
updated_at descIf you’re using Steampipe, you can install the GitHub plugin like this:
steampipe plugin install githubthen run the query in the Steampipe CLI or in any Postgres client that can connect to Steampipe’s instance of Postgres.
But if you want to do the same thing in your own instance of Postgres, you can install the plugin in a different way.
$ sudo /bin/sh -c "$(
curl -fsSL https://steampipe.io/install/postgres.sh)"
Enter the plugin name: github
Enter the version (latest):
Discovered:
- PostgreSQL version: 14
- PostgreSQL location: /usr/lib/postgresql/14
- Operating system: Linux
- System architecture: x86_64
Based on the above, steampipe_postgres_github.pg14.linux_amd64.tar.gz
will be downloaded, extracted and installed at: /usr/lib/postgresql/14
Proceed with installing Steampipe PostgreSQL FDW for version 14 at
/usr/lib/postgresql/14?
- Press 'y' to continue with the current version.
- Press 'n' to customize your PostgreSQL installation directory
and select a different version. (Y/n):
Downloading steampipe_postgres_github.pg14.linux_amd64.tar.gz...
###############################################################
############################ 100.0%
steampipe_postgres_github.pg14.linux_amd64/
steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_
github.so
steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_
github.control
steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_
github--1.0.sql
steampipe_postgres_github.pg14.linux_amd64/install.sh
steampipe_postgres_github.pg14.linux_amd64/README.md
Download and extraction completed.
Installing steampipe_postgres_github in /usr/lib/postgresql/14...
Successfully installed steampipe_postgres_github extension!
Files have been copied to:
- Library directory: /usr/lib/postgresql/14/lib
- Extension directory: /usr/share/postgresql/14/extension/Now connect to your server as usual, using psql or another client, most typically as the postgres user. Then run these commands, which are typical for any Postgres foreign data wrapper. As with all Postgres extensions, you start like this:
CREATE EXTENSION steampipe_postgres_fdw_github;To use a foreign data wrapper, you first create a server:
CREATE SERVER steampipe_github FOREIGN DATA WRAPPER
steampipe_postgres_github OPTIONS (config 'token="ghp_..."');Use OPTIONS to configure the extension to use your GitHub access token. (Alternatively, the standard environment variables used to configure a Steampipe plugin—it’s just GITHUB_TOKEN in this case—will work if you set them before starting your instance of Postgres.)
The tables provided by the extension will live in a schema, so define one:
CREATE SCHEMA github;Now import the schema defined by the foreign server into the local schema you just created:
IMPORT FOREIGN SCHEMA github FROM SERVER steampipe_github INTO github;Now run a query!
The foreign tables provided by the extension live in the github schema, so by default you’ll refer to tables like github.github_my_repository. If you set search_path = 'github', though, the schema becomes optional and you can write queries using unqualified table names. Here’s a query we showed last time. It uses the GitHub_search_repository which encapsulates the GitHub API for searching repositories.
Suppose you’re looking for repos related to PySpark. Here’s a query to find repos whose names match “pyspark” and report a few metrics to help you gauge activity and popularity.
select
name_with_owner,
updated_at, -- how recently updated?
stargazer_count -- how many people starred the repo?
from
github_search_repository
where
query = 'pyspark in:name'
order by
stargazer_count desc
limit 10;
+---------------------------------------+------------+---------------+
|name_with_owner |updated_at |stargazer_count|
+---------------------------------------+------------+---------------+
| AlexIoannides/pyspark-example-project | 2024-02-09 | 1324 |
| mahmoudparsian/pyspark-tutorial | 2024-02-11 | 1077 |
| spark-examples/pyspark-examples | 2024-02-11 | 1007 |
| palantir/pyspark-style-guide | 2024-02-12 | 924 |
| pyspark-ai/pyspark-ai | 2024-02-12 | 791 |
| lyhue1991/eat_pyspark_in_10_days | 2024-02-01 | 719 |
| UrbanInstitute/pyspark-tutorials | 2024-01-21 | 400 |
| krishnaik06/Pyspark-With-Python | 2024-02-11 | 400 |
| ekampf/PySpark-Boilerplate | 2024-02-11 | 388 |
| commoncrawl/cc-pyspark | 2024-02-12 | 361 |
+---------------------------------------+------------+---------------+If you have a lot of repos, the first run of that query will take a few seconds. The second run will return results instantly, though, because the extension includes a powerful and sophisticated cache.
And that’s all there is to it! Every Steampipe plugin is now also a foreign data wrapper that works exactly like this one. You can load multiple extensions in order to join across APIs. Of course, you can join any of these API-sourced foreign tables with your own Postgres tables. And to save the results of any query, you can prepend “create table NAME as” or “create materialized view NAME as” to a query to persist results as a table or view.
Using a Steampipe Plugin as a SQLite Extension That Provides Virtual Tables
Visit Steampipe downloads to find the installer for your OS and run it to acquire the SQLite distribution of the same plugin.
$ sudo /bin/sh -c "$(curl -fsSL https://steampipe.io/install/sqlite.sh)"
Enter the plugin name: github
Enter version (latest):
Enter location (current directory):
Downloading steampipe_sqlite_github.linux_amd64.tar.gz...
############################################################
################ 100.0%
steampipe_sqlite_github.so
steampipe_sqlite_github.linux_amd64.tar.gz downloaded and
extracted successfully at /home/jon/steampipe-sqlite.Here’s the setup, and you can place this code in ~/.sqliterc if you want to run it every time you start sqlite.
.load /home/jon/steampipe-sqlite/steampipe_sqlite_github.so
select steampipe_configure_github('
token="ghp_..."
');Now you can run the same query as above. Here, too, the results are cached, so a second run of the query will be instant.
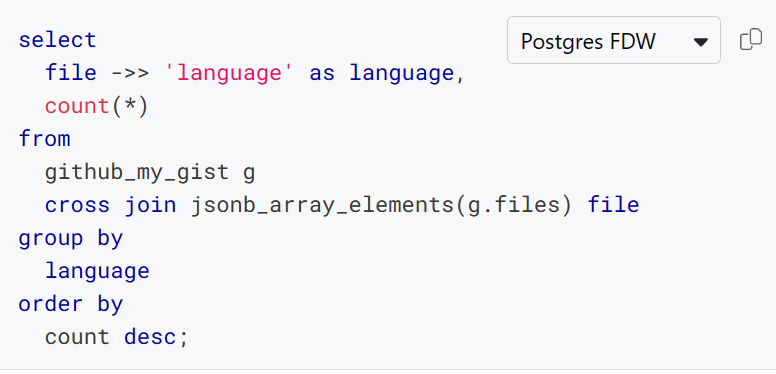
What about the differences between Postgres-flavored and SQLite-flavored SQL? The Steampipe hub is your friend! For example, here are Postgres and SQLite variants of a query that accesses a field inside a JSON column in order to tabulate the languages associated with your gists.
Postgres
SQLite
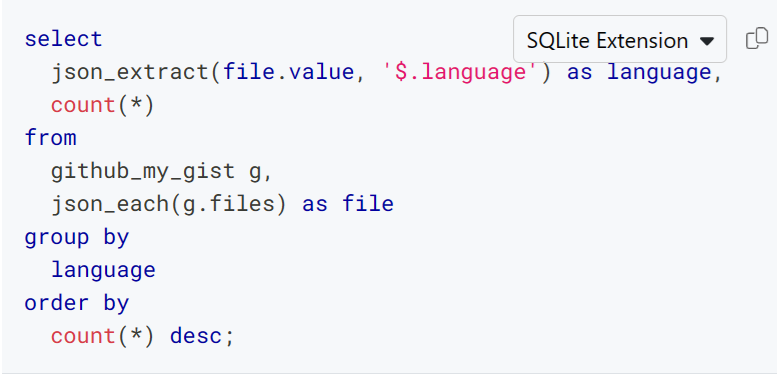
The github_my_gist table reports details about gists that belong to the GitHub user who is authenticated to Steampipe. The language associated with each gist lives in a JSONB column called files, which contains a list of objects like this.
{
"size": 24541,
"type": "text/markdown",
"raw_url": "https://gist.githubusercontent.com/judell/49d66ca2a5d2a3b
"filename": "steampipe-readme-update.md",
"language": "Markdown"
}The functions needed to project that list as rows differ: in Postgres you use jsonb_array_elements and in SQLite it’s json_each.
As with Postgres extensions, you can load multiple SQLite extensions in order to join across APIs. You can join any of these API-sourced foreign tables with your own SQLite tables. And you can prepend create table NAME as to a query to persist results as a table.
Using a Steampipe Plugin as a Standalone Export Tool
Visit Steampipe downloads to find the installer for your OS, and run it to acquire the export distribution of a plugin—again, we’ll illustrate using the GitHub plugin.
$ sudo /bin/sh -c "$(curl -fsSL https://steampipe.io/install/export.sh)"
Enter the plugin name: github
Enter the version (latest):
Enter location (/usr/local/bin):
Created temporary directory at /tmp/tmp.48QsUo6CLF.
Downloading steampipe_export_github.linux_amd64.tar.gz...
##########################################################
#################### 100.0%
Deflating downloaded archive
steampipe_export_github
Installing
Applying necessary permissions
Removing downloaded archive
steampipe_export_github was installed successfully to
/usr/local/bin
$ steampipe_export_github -h
Export data using the github plugin.
Find detailed usage information including table names,
column names, and examples at the Steampipe Hub:
https://hub.steampipe.io/plugins/turbot/github
Usage:
steampipe_export_github TABLE_NAME [flags]
Flags:
--config string Config file data
-h, --help help for steampipe_export_github
--limit int Limit data
--output string Output format: csv, json or jsonl
(default "csv")
--select strings Column data to display
--where stringArray where clause dataThere’s no SQL engine in the picture here; this tool is purely an exporter. To export all your gists to a JSON file:
steampipe_export_github github_my_gist --output json > gists.jsonTo select only some columns and export to a CSV file:
steampipe_export_github github_my_gist --output csv --select
"description,created_at,html_url" > gists.csvYou can use --limit to limit the rows returned and --where to filter them, but mostly you’ll use this tool to quickly and easily grab data that you’ll massage elsewhere, for example, in a spreadsheet.
Tap into the Steampipe Plugin Ecosystem
Steampipe plug-ins aren’t just raw interfaces to underlying APIs. They use tables to model those APIs in useful ways. For example, the github_my_repository table exemplifies a design pattern that applies consistently across the suite of plug-ins. From the GitHub plugin’s documentation:
You can own repositories individually, or you can share ownership of repositories with other people in an organization. The
github_my_repositorytable will list repos that you own, that you collaborate on, or that belong to your organizations. To query ANY repository, including public repos, use thegithub_repositorytable.
Other plug-ins follow the same pattern. For example, the Microsoft 365 plugin provides both microsoft_my_mail_message and microsoft_mail_message, and the plugin provides googleworkspace_my_gmail_message and googleworkspace_gmail. Where possible, plug-ins consolidate views of resources from the perspective of an authenticated user.
While plug-ins typically provide tables with fixed schemas, that’s not always the case. Dynamic schemas, implemented by the Airtable, CSV, Kubernetes, and Salesforce plug-ins (among others) are another key pattern. Here’s a CSV example using a standalone Postgres FDW.
IMPORT FOREIGN SCHEMA csv FROM SERVER steampipe_csv INTO csv
OPTIONS(config 'paths=["/home/jon/csv"]');Now all the .csv files in /home/jon/csv will automagically be Postgres foreign tables. Suppose you keep track of valid owners of EC2 instances in a file called ec2_owner_tags. Here’s a query against the corresponding table.
select * from csv.ec2_owner_tags;
owner | _ctx
----------------+----------------------------
Pam Beesly | {"connection_name": "csv"}
Dwight Schrute | {"connection_name": "csv"}You could join that table with the AWS plugin’s aws_ec2_instance table to report owner tags on EC2 instances that are (or are not) listed in the CSV file.
select
ec2.owner,
case
when csv.owner is null then 'false'
else 'true'
end as is_listed
from
(select distinct tags ->> 'owner' as owner
from aws.aws_ec2_instance) ec2
left join
csv.ec2_owner_tags csv on ec2.owner = csv.owner;
owner | is_listed
----------------+-----------
Dwight Schrute | true
Michael Scott | falseAcross the suite of plug-ins there are more than 2,300 predefined fixed-schema tables that you can use in these ways, plus an unlimited number of dynamic tables. And new plug-ins are constantly being added by Turbot and by Steampipe’s open source community. You can tap into this ecosystem using Steampipe or Turbot Pipes, from your own Postgres or SQLite database, or directly from the command line.