The evolution and expanding utility of Ray
There are growing numbers of users and contributors to the framework, as well as libraries for reinforcement learning, AutoML, and data science.
 Chess cube (source: Pixabay)
Chess cube (source: Pixabay)
In a recent post, I listed some of the early use cases described in the first meetup dedicated to Ray—a distributed programming framework from UC Berkeley’s RISE Lab. A second meetup took place a few months later, and both events featured some of the first applications built with Ray. On the development front, the core API has stabilized and a lot of work has gone into improving Ray’s performance and stability. The project now has around 5,700 stars on GitHub and more than 100 contributors across many organizations.
At this stage of the project, how does one describe Ray to those who aren’t familiar with the project? The RISE Lab team describes Ray as a “general framework for programming your cluster or cloud.” To place the project into context, Ray and cloud functions (FaaS, serverless) currently sit somewhere in the middle between extremely flexible systems on one end or systems that are much more targeted and emphasize ease of use. More precisely, users currently can avail of extremely flexible cluster management and virtualization tools on one end (Docker, Kubernetes, Mesos, etc.), or domain specific systems on the other end of the flexibility spectrum (Spark, Kafka, Flink, PyTorch, TensorFlow, Redshift, etc.).

Learn faster. Dig deeper. See farther.
How does this translate in practice? Ray’s support for both stateless and stateful computations, and fine-grained control over scheduling allows users to implement a variety of services and applications on top of it:

Libraries on top of Ray are already appearing: RLlib (scalable reinforcement learning), Tune (a hyperparameter optimization framework), and a soon-to-be-released library for streaming are just a few examples. As I describe below, I expect more to follow soon.
That’s all well and good, but most developers, data scientists, and researchers aren’t necessarily looking to write libraries. They are likely to be interested in tools that already provide libraries they can use. If you are a data scientist or developer who uses Python, there are several reasons you should start looking into Ray:
- Modin lets you scale your pandas workflows by changing one line of code. Given that many data scientists already love using pandas, Modin is an extremely simple way to scale and speed up existing code.
- Scalable data science: It has not gone unnoticed that Ray provides a simple way for Python users to parallelize their code. At a recent UC Berkeley course—Data Science 100—co-taught by one of the creators of Jupyter, Ray was the focus of a lecture on distributed computing.
- Reinforcement learning (RL): RL is one of those topics that data scientists are beginning to explore. But just as many machine learning users take advantage of existing libraries (e.g., scikit-learn), most RL users won’t be writing libraries and tools from scratch. The good news is that RLlib provides both a unified API for different types of RL training, and all of RLlib’s algorithms are distributed. Thus, both RL users and RL researchers benefit from using RLlib.
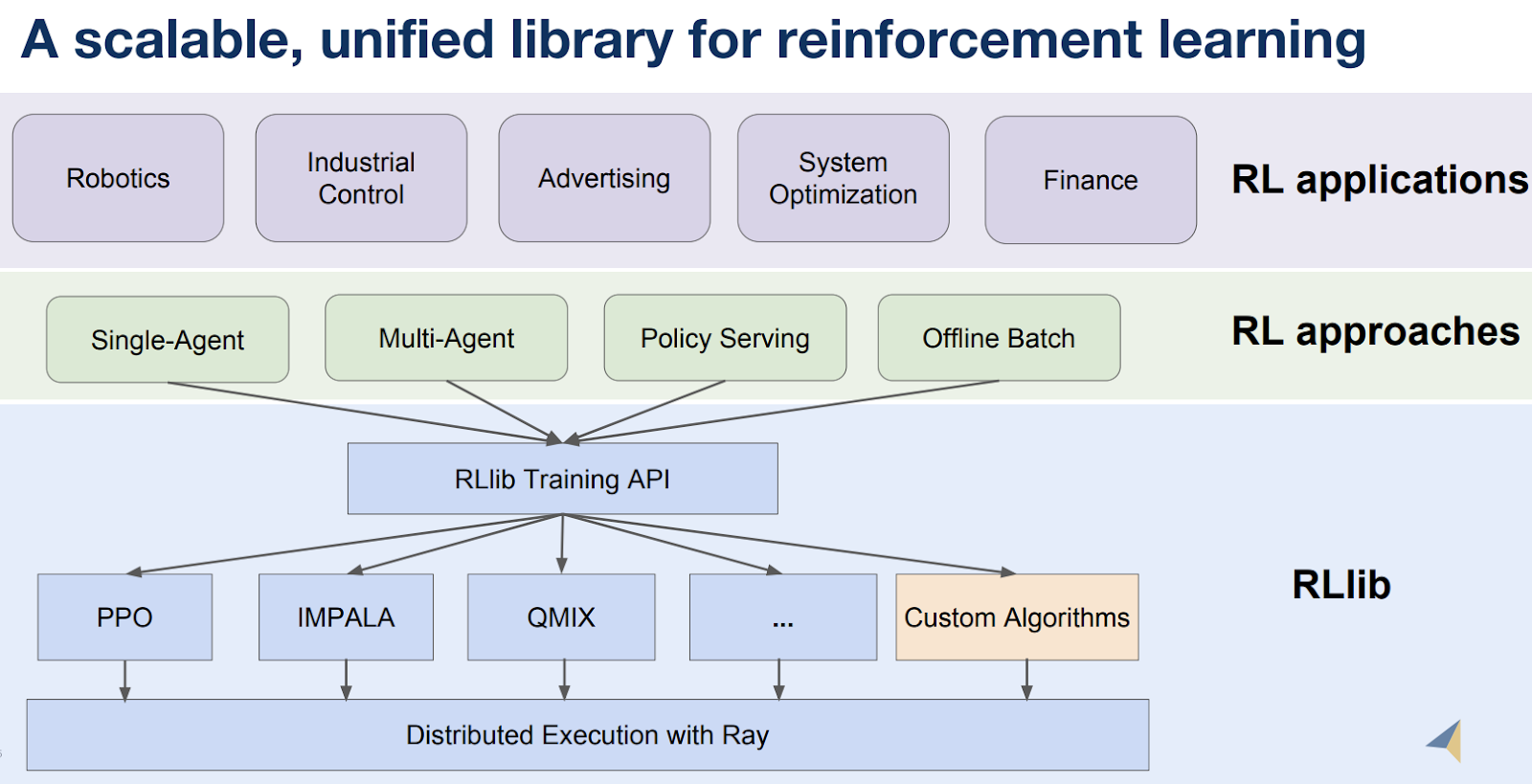
- AutoML: In a recent post, we described tools for automating various stages of machine learning projects—with model building being an important component. Ray users can already take advantage of Tune, a scalable hyperparameter optimization framework. Hyperparameter tuning is a critical and common step in machine learning model exploration and building. There are also other AutoML projects that use Ray, and hopefully some will be released into open source in the near future.
What about actual usage? The growing number of project contributors, along with the rise of libraries and tools has translated into additional use cases and production deployments of Ray. In a previous post, I listed a UC Berkeley research group investigating mixed-autonomy mobility and Ant Financial as organizations already using Ray (Ant Financial has several Ray use cases in production). Since then, I’ve heard of other industry use cases in various settings:
- Financial services and industrial automation applications
- Ray is being used in text mining, in the construction of knowledge graphs, and for graph queries
- Companies exploring the use of Ray for real-time recommendation systems—which involves learning models against live data.
There are also a growing roster of research groups in AI, machine learning, robotics, and engineering that have adopted Ray. With Ray beginning to be available on cloud platforms—Amazon SageMaker RL includes Ray—I expect to hear of many more interesting case studies involving Ray.
In closing, this is a great time to explore Ray. The core API is stable, libraries are improving and expanding, more production deployments are emerging, and (most importantly) the community of users and contributors is growing.
Related content:
- From the RISE Lab team: “Programming in Ray—Tips for first-time users”
- “Notes from the first Ray meetup”
- Cathy Wu on “Reinforcement learning for mixed autonomy mobility”
- Robert Nishihara and Philipp Moritz on “How Ray makes continuous learning accessible and easy to scale”
- “Deep automation in machine learning”
- Danny Lange on “Unleashing the potential of reinforcement learning”
- “Overcoming barriers to AI adoption”